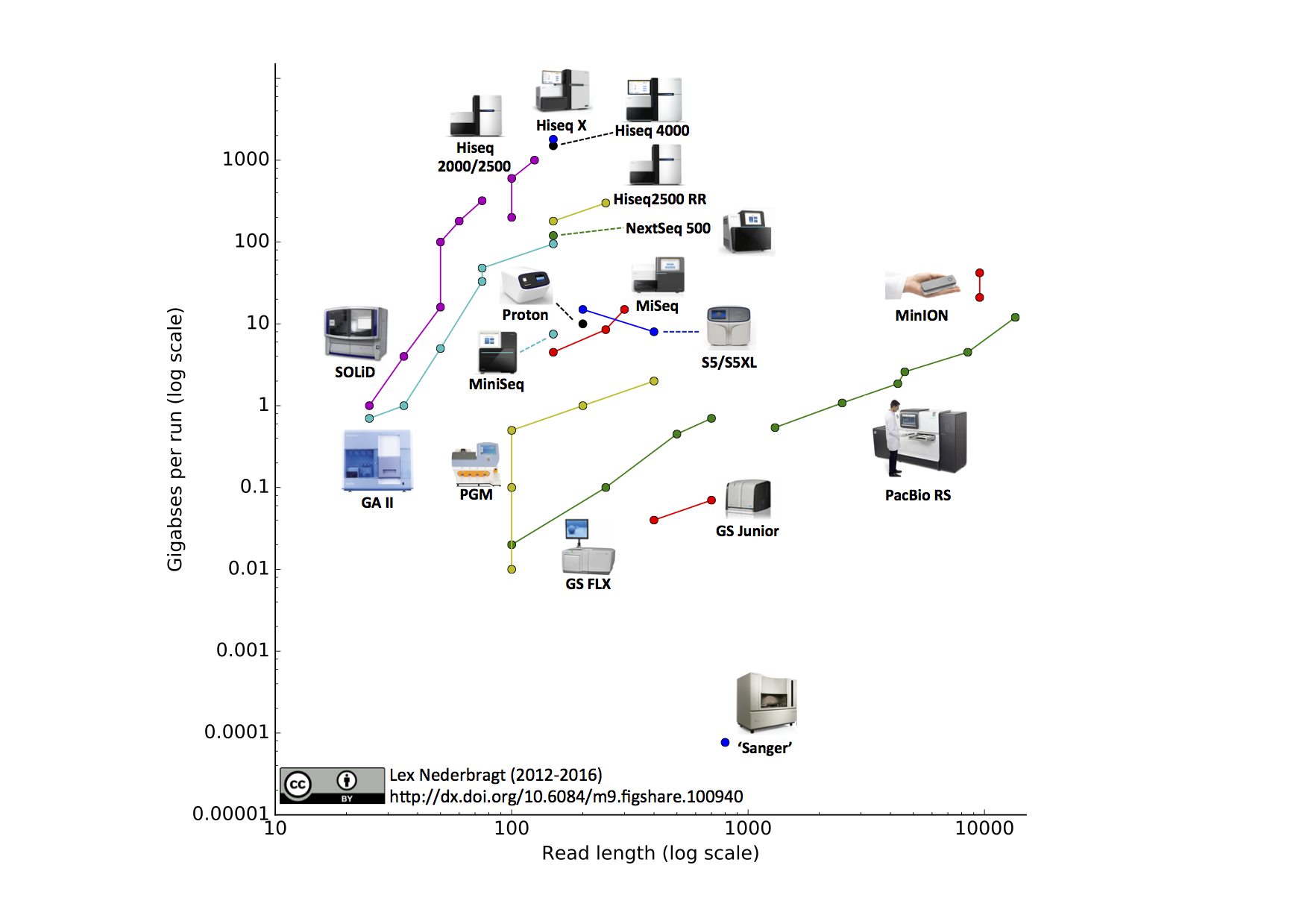
[Adapted from Titus Brown’s blog post]
Titus Brown has been so kind as to invite me to co-instruct this week-long workshop (thanks!). So I thought to make a bit of a commercial for it:
Are you interested in
- Getting started with, or getting better at, teaching the Analysis of High Throughput Sequencing Data
- Hands-on training in good pedagogical practice
- Becoming a certified Software/Data Carpentry instructor
- Learning how to repurpose and remix online training materials for your own needs
… then this one-week workshop is for you!
When: June 18-June 25, 2017 (likely we’ll only use Monday-Friday).
Where: University of California, Davis, USA
Instructors: Karen Word, C. Titus Brown, and Lex Nederbragt
This workshop is intended for people interested in teaching, reusing
and repurposing the Software Carpentry, Data Carpentry, or Analyzing High Throughput Sequencing Data materials. We envision this course being most useful to current teaching-intensive faculty, future teachers and trainers, and core facilities that are developing training materials.
Attendees will learn about and gain practice implementing evidence-based teaching practices. Common pitfalls specific to novice-level instruction and bioinformatics in particular will be discussed, along with associated troubleshooting strategies. Content used in prior ANGUS workshops on Analyzing High Throughput Sequencing Data will be used for all practice instruction, and experienced instructors will be on hand to address questions about implementation.
Attendees of this workshop may opt to remain at the following ANGUS two-week workshops so that they can gain hands-on experience in preparing and teaching a lesson.
This week-long training will also serve as Software/Data Carpentry Instructor Training.
Attendees should have significant familiarity with molecular biology and basic experience with the command line.
We anticipate a class size of approximately 25, with 3-6 instructors.
The official course website is here.
Apply here!
Applications will close March 17th.
The course fee will be $350 for this workshop. On campus housing may not be available for this workshop, but if it is, room and board will be approximately $500/wk additional (see venue information). (Alternatives will include local hotels and Airbnb.)
If you have questions, please contact dibsi.training@gmail.com.