(Cross-posted at contig.wordpress.com)

Typical Newbler assembly output
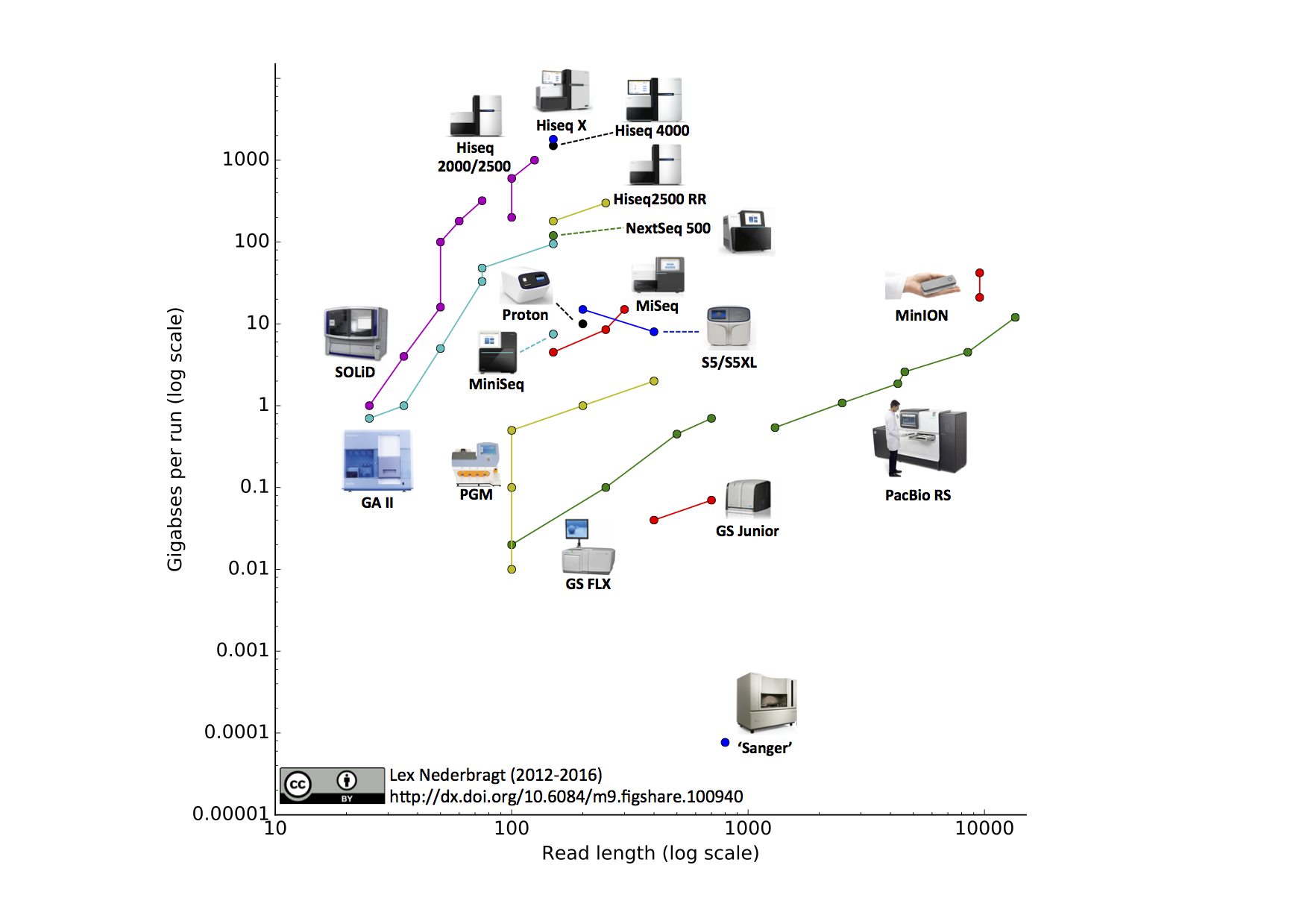
The Newbler assembler and mapper (gsAssembler, gsMapper) was developed especially for working with the reads from the Roche/454 Life Science sequencing technology. It is one of the best programs to deal with this type of data, scoring well in the assemblathon 2 competition. Newbler has been used for many large and small genome assemblies (numerous bacteria, Atlantic cod, bonobo, tomato, to name a few). Recently, Newbler has added support for using multiple sequencing technologies, making it one of the few hybrid assembly programs available. At the Advances in Genome Biology and Technology (AGBT) in 2013, Roche announced having used the Newbler program with a hybrid 454 and Illumina dataset to improve upon the human genome.
However, the Newbler program is not open source. Luckily, researchers only need to fill out an online form to get a free copy of the software. Still, this has hampered the wide-spread adoption of this program. Newbler, for example, was not included in assembly evaluations like GAGE and GAGE-B. That Roche/454 does not want to make the source code for Newbler available is partly understandable from a commercial standpoint: at least one competitor technology (Life Tech/Ion Torrent) with a similar sequencing error-model could benefit from access to the code. In fact, in a blog post, I showed Newbler to be superior to an open-source program when assembling Ion Torrent mate-pair data.
More worringly is that the hundreds of projects that used Newbler as part of the analysis are fundamentally irreproducible without the source code for each of the different versions. This is especially the case for projects, such as the Atlantic cod genome project, that have been given access to development versions of the code, incorporating elements not available to the general community.
Last October, Roche announced it will shutdown its 454 sequencing business in mid-2016. Whatever one may feel about this decision, this further strengthens the argument for Roche/454 to make the Newbler source code open source. After the 454 shutdown, Newbler is otherwise likely to disappear too, meaning that large swathes of the literature cannot be recapitulated from the raw data. Also, long after the 454 shutdown, many researchers will have to process their 454 sequencing data, and many may still want to rely on Newbler for that purpose.
There are several other reasons why I feel the research community should be given access to the source code of Newbler. Newbler represents a very valuable contribution to the field of genome assembly and mapping. Software developers can learn from the algorithms and implementations of the Newbler code, opening up for reusing these in other programs. Also, there is the hope that developers will improve upon the program, for example by adding support for other sequencing technologies, or assembling with reads longer than the current maximum of 2 kbp.
So I hereby ask the readers of this blog for help: I have set up an online petition asking for Roche/454 to make the Newbler source code available at the latest at the time of the 454 shutdown. Please sign the petition here. Additionally, spread the word (e.g., on twitter or your own blog). Thanks in advance!
I intend to hand over the results of the petition to a Roche representative at the Advances in Genome Biology and Technology (AGBT) meeting (February 12-15, 2014).
Finally, feel free to use the comments to tell me about your Newbler experiences!
(Thanks to Nick Loman for his constructive comments on an earlier version of this post)